
印刷文本OCR
- 项目简介
- 印刷文本OCR技术是指从自然场景图片中检测和识别出其中印刷体文字,包含不同材质、尺寸、背景上的印刷文本,如常用卡证、票据、公文、条幅等,文本存在一定程度的扭曲和变形。印刷文本OCR的检测任务同手写文本OCR。
- 评价指标

- 说明:
- 1.若准确率+召回率=0时,则Hmean=0;
- 2.在文本框检测任务中,评测准确率和召回率时印刷文字框检测正确与否的标准参照icdar15标准(http://rrc.cvc.uab.es/?ch=4&com=tasks)。具体评判检测过程如下:
- 1)印刷文字框检测使用
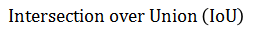 来判断。当检测文本框与标准文本框IoU大于某个阈值时
来判断。当检测文本框与标准文本框IoU大于某个阈值时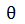 (通常设置为
(通常设置为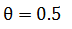 ),则认为该检测框命中标准文本框;
IoU的计算方式如下:
),则认为该检测框命中标准文本框;
IoU的计算方式如下: - Area of Overlap:检测的印刷文字框与标准文字框之间的交集
- Area of Union:检测的印刷文字框与标准文字框之间的并集
- 2)所有检测框和标准框都只能用一次,再次匹配被判为未命中;
- 3)标准框分为有效框和无效框(有文字但由于模糊等原因无法标注的标准框),如果检测框命中无效框, 则忽略该检测框;
- 4)若检测框未命中标准框,但文字识别正确,则记作未命中。
- 5)计算召回率和准确率
- 3.在文字识别任务中,文字框命中的标准与检测任务相同。编辑距离(edit_distance)为识别结果和标准文本的编辑距离,其计算方式如下: 使用“插入(insertion)”、“删除(Deletion)”、“置换(substitution)”三种基本操作,以最小的操作数将识别结果转换为标准文本,则所需操作数被记为编辑距离。然后编辑距离除以标准文本长度后再对所有标准文本的总检测框求平均,具有最低平均编辑距离的模型认为识别性能最好。
- 竞赛测试数据集
- 测试数据集包含不同来源的包含印刷文字的图像,共6,000张印刷文字图像。图像来自自然场景图片、街拍图、海报,以及手机电脑截屏等,并进行脱密处理。
- 任务输入输出格式
- 1.(输入)测试图像文件夹路径;
2.(输出)检索结果:要求参评单位将所有检索结果整理为一份CSV文件,文本的坐标顺序为依照阅读首字符的左上角开始顺时针顺序存储,每一项用制表符'\t'分割,每一行具体格式如下:(所有输出以UTF-8无BOM格式编码) - 其中第N个矩形框坐标的格式如下:


测试图像1文件名\t第1个矩形框坐标\t第1个矩形框的识别结果\t…\t第N个矩形框坐标\t第N个矩形框的识别结果

cde0c3a3-32e0-40ee-aabd-714c3405f28f.jpg\t(6,7,86,7,90,330,5,330)\t菲斯丹琦\t\nb9ecdfee-a81e-4522-a496-9dd1b50da7c6.jpg\t(6,7,86,7,90,330,5,330)\t清凉滋味\t\n
……


